
Bearbeitungszeit: 23.Okt 2025 – 8.November 2025 (zuletzt: 14:50h)
Dieser Text gehört zur Seite Ankündigung & Erweiterter Bericht zu ‚‚Ist KI nun der Feind oder unser Freund?‘, Vortrag Nr.3 aus der Reihe ‚Mensch & KI : Risiko oder Chance?‘
Autor: Gerd Doeben-Henisch
KONTAKT : info@oksimo.org

ERWEITERTER BERICHT ZUM VORTRAG : ‚Ist KI nun der Feind oder unser Freund?‘, Vortrag Nr.3 aus der Reihe ‚Mensch & KI : Risiko oder Chance?‘
Von
Prof. Dr. Gerd Doeben-Henisch
Emeritierter Professor für Informatik (KI, Mensch-Maschine Interaktion) und Wissenschaftsphilosoph
Dieser Text geht zurück auf eine öffentliche Veranstaltung am 21.Oktober 2025 im Bürgertreff von 61137 Schöneck-Kilianstädten, 20-22h. Der Autor entwickelte dort, angereichert mit vielen Gesprächsanteilen, ob und wie eine KI generell (nicht nur ein Dialog-Chatbot wie chatGPT) für uns Menschen zum ‚Feind‘ werden kann oder auch zum ‚Freund‘. Erste Grenzen der Leistungsfähigkeit einer KI wurden sichtbar. Daraus ergaben sich wieder interessante Anschlussfragen für eine nächste Veranstaltung (25.Nov 2025).
Das inflationäre Feindschema und der diffuse Freund …
Als Autor beschäftige ich mich seit gut 45 Jahren mit dem Thema ‚Wissen‘ bei Menschen und Maschinen. Der lange Zeitraum gab Gelegenheit, dieses Thema aus der Sicht verschiedener Disziplinen zu betrachten und auch zu untersuchen. Ist die ‚Vielstimmigkeit‘ der unterschiedlichen Disziplinen schon immer eine Herausforderung gewesen, da integrierende wissenschaftliche Modelle schlicht fehlen, begannen mit der Popularität der neuen dialogischen Chatbots ab Herbst 2022 alle Dämme zu brechen. Auf einen Schlag erschienen in der Zeit danach nahezu auf allen medialen Kanälen und in allen Branchen täglich viele Artikel. Dazu gab es weiterhin die vielen Science Fiction Romane, Filme und Comics, die auch ohne wissenschaftlichen Anspruch die Vorstellungswelt von vielen Bürgern erreichen und automatisch prägten, auch wenn dies den meisten nicht unbedingt bewusst war bzw. immer noch nicht bewusst ist.
In einer solchen mit vielen Bildern aufgeladenen Situation werden alle Begriffe zu ‚oszillierenden Vorstellungen‘, deren ‚harter Kern‘ nur noch schwer — wenn überhaupt — zu fassen ist. Die Vision von der irgendwann übermächtigen allwissenden KI hat eine lange Tradition und lebt heute in vielen — teils ‚modernisierten‘ — Varianten weiter, und auch die Variante von der KI als ‚Freund‘ hält sich durch. Die Vision des Freundes erscheint hier als der emotionale Gegenpol, der eine Art ‚Gleichgewicht‘ erzeugt, um die Bilder einer ‚übermächtigen KI‘ ein wenig abzuschwächen.
Kann man in einer solchen vielstimmigen Situation dann also nichts mehr sagen, weil alles im ‚Rauschen des Vielen‘ untergeht?
Eine gewisse Chance des Nachdenkens über ‚Mensch & KI‘ besteht darin, sich auf jene Strukturen zu besinnen, die uns allen gemeinsam sind: die konkreten Situationen des Alltags, in die wir mit unserem Körper eingebunden sind, und wo sich auch alle anderen unausweichlich befinden. Selbst wenn sich jemand unter’KI‘ zunächst nichts vorstellen kann, wenn es eine KI gibt, die im Kontext des Alltags ‚Wirkungen erzielt‘, dann hat man gemeinsame überprüfbare Anhaltspunkte, über die wir reden können.
Im Fall von uns selbst, von uns Menschen, ist es ja nicht anders: Niemand kann ‚in den anderen‘ hineinschauen. Wir sind immer darauf angewiesen, wie wir uns wechselseitig wahrnehmen und erleben können. Und die ‚Vorstellungen der Menschen über sich selbst‘ waren viele Jahrtausende sehr ‚fantasievoll‘ und — wie wir heute teilweise wissen können — einfach falsch. Obwohl die modernen Wissenschaft in den letzten 150 Jahren das Wissen über den Körper des Menschen samt vieler intern ablaufenden Prozesse geradezu dramatisch erweitern konnte, sind viele wichtige Fragen bislang immer noch nicht gelöst. Das Denken der modernen Wissenschaften in ‚Einzeldisziplinen‘ bildet eine große Hürde für die Entwicklung einer ‚umfassenden systemischen Sicht‘ auf unseren Körper als Ganzes, auf das Zusammenspiel der vielen einzelnen Funktionalitäten mit all den begleitenden ’subjektiven Prozessen‘. Und dies ist ja nur ein kleiner Teil jener Wirklichkeit, in welcher der einzelne Mensch vorkommt.
WAS IST WAS?
Für die Klärung, ob eine KI für einen Menschen so gefährlich werden kann, dass man diese als potentiellen ‚Feind‘ für uns Menschen bezeichnen muss oder, ganz im Gegenteil, durch seine Unterstützungsleistungen als ‚Freund‘, ist es hilfreich, sich vorab einige grundlegende Eigenschaften von einer ‚KI‘ — und auch von uns Menschen! — klar zu machen.
KI : Hardware – Betriebssystem – Spezielle Anwendungssoftware – Benutzerschnittstelle Internet – Plattformanwendung
Wenn wir pauschal von einer ‚KI‘ sprechen, dann kann dies so verstanden werden, als ob wir uns einem ‚konkreten Objekt‘ gegenüber befinden, mit bestimmten ‚Eigenchaften‘, welche — für nicht wenige — mit Bezug auf uns Menchen irgendwie ‚Ähnlichkeiten‘ aufweisen. Die Realität ist eine andere.
Eine ‚KI‘ ist in erster Linie eine Software (ein Programm, ein Algorithmus), das man als eine ‚Liste von Befehlen‘ verstehen kann. Eine Software ‚alleine für sich‘ ist aber letztlich ein ‚Nichts‘, da ihre ‚Befehle‘ nur dann eine Wirkung entfalten können, wenn es einen ‚Empfänger für diese Befehle‘ gibt.
Im einfachen Fall — so in der Frühzeit der Computer ab ca. 1935 [1] — wurde die Software mit ihren Befehlen direkt in eine ‚Maschine‘ (die ‚Hardware‘) eingegeben. Das ‚Format‘ der Software bestand dabei aus einer Reihe von Zahlen (erst Dualsystem, dann komplexere Codes), die von der Hardware direkt empfangen und direkt ‚umgesetzt‘ wurden. Die Hardware ‚übersetzte‘ die Zahlen in ‚Maschinenzustände‘, welche partiell dann als die ‚Antworten‘ des Systems für den Benutzer erfahrbar wurden.
Dies alles war für die menschlichen Benutzer sehr mühsam und für die Anbieter der Hardware sehr umständlich. Eine intensive dynamische Entwicklung setzte ein, um die Zusammenarbeit von Menschen, Programmen und Hardware immer weiter zu verbessern.
Für die Kommunikation einer Software mit der Hardware wurde eine ‚Zwischenschicht‘ erfunden, auch eine Software, aber diese war ausschließlich dazu da, die Interaktion mit der Hardware zu vereinheitlichen. Diese Software, die dann zwischen der Hardware und einer ’speziellen Anwendungssoftware vermittelnd‘ aktiv war, nannte man das ‚Betriebssystem‘ (Englisch: ‚operating system (OS)‘)[2]. Während sich die Hardware immer wieder verändern konnte, sorgte das Betriebssystem dafür, dass spezielle Anwendungssoftware immer die gleiche Kontaktoberfläche — auch ‚Schnittstelle‘ genannt — vorfand; dies vereinfachte die Erstellung von ‚Anwendungssoftware‘ gewaltig.
Zusätzlich zu dieser Arbeitsteilung ‚Hardware – Betriebssystem – Anwendungssoftware‘ entwickelte sich auch die direkte ‚Mensch-Maschine Schnittstelle‘ (‚Benutzerschnittstelle‘, Englisch: ‚User Interface (UI)‘) rasant weiter. [2b] Bekannt sind grafische Bildschirme mit einer ‚Maus‘ und einer Tastatur, Audioausgabe und -eingabe, und vieles mehr. Wir haben also die Grundkonstellation ‚Hardware – Betriebssystem – Anwendungssoftware – Benutzerschnittstelle‘.
Mit dem Aufkommen des Internets [3] eröffnete sich die Möglichkeit, dass einzelne Rechner miteinander so verbunden werden, dass sie direkt miteinander ‚Daten‘ austauschen können. Zusätzlich entwickelten sich auch ‚Plattformen‘ (‚Clouds‘), die immer umfassendere Dienste auf der Plattform selbst anbieten (eine ‚Plattformanwendung‘), die dann vom Benutzer über einen ‚Webbrowser‘ aufgerufen und genutzt werden können.
An dieser Stelle betreten z.B. die ‚Chatbots der generativen KI‘ die Bühne. Irgendwo auf der Welt startet ein Benutzer einen Browser (Handy, Laptop, PC, …), wählt sich in die ‚KI Anwendung‘ ein und beginnt einen ‚Dialog‘ mit einem Chatbot, welcher die Schnittstelle (das ‚Interface‘) zu der dahinter liegenden KI-Anwendung bildet.[4]
Wenn man im Falle einer interaktiven Internetanwendung ‚verstehen‘ will, welche Software man da vor sich hat, was diese genau leisten kann, dann gibt es mindestens zwei unterschiedliche Vorgehensweisen: (1) Man protokolliert seine eigenen Interaktionen mit der Anwendung — oder die von anderen Nutzern –, und versucht dann aus der ‚Abfolge dieser Interaktionen‘ sich ein Bild zu machen, ‚was/ wen‘ man da ‚vor sich hat‘. [5] Oder (2) man schaut sich die Software näher an, mit welcher die Eigenschaften und das Verhalten eines Chatbots mit der Technologie der sogenannten ‚generativen KI‘ erzeugt wird. Das Vorgehen nach Methode (2) erlaubt grundsätzliche Betrachtungen, über welche Eigenschaften solch eine Software ‚prinzipiell‘ verfügt, ohne dass man dadurch die ‚Wirkung des konkreten Verhaltens auf Menschen‘ erfassen kann. Das Vorgehen nach Methode (1) erlaubt zwar annähernd die Erfassung der Wirkung auf Menschen, kann aber nur bedingt ‚prinzipielle Aussagen‘ treffen.
Soweit als erste ‚Einstimmung‘ auf die reale Struktur ‚hinter dem Wort KI‘.
ANMERKUNGEN
[1] Zur Geschichte des Computers siehe hier: https://de.wikipedia.org/wiki/Geschichte_des_Computers In dieser Darstellung wird auch viel ‚Vorgeschichte‘ berichtet. Die Geschichte der heute im Einsatz befindlichen Computer beginnt in dieser Darstellung aber erst 1935 (siehe den einschlägigen Abschnitt)
[2] Für einen vertiefenden Überblick siehe hier: https://de.wikipedia.org/wiki/Betriebssystem
[2b] Einige weiterführende Gedanken finden sich hier: https://de.wikipedia.org/wiki/Benutzerschnittstelle
[3] Für einen ersten Überblick siehe: https://de.wikipedia.org/wiki/Internet
[4] Eine Beschreibung von ‚generativer KI‘ aus mathematischer Sicht findet sich hier: https://de.wikipedia.org/wiki/Generatives_KI-Modell . Eine eher anwendungsorientierte Sicht wurde im Vortrag Nr.2 beschrieben: https://www.oksimo.org/2025/09/11/mensch-ki-risiko-oder-chance-wie-denkt-chatgpt-erweiterter-bericht-vom-mittwoch-3-sept-2025-20-22h/
[5] Diese Vorgehensweise weist starke strukturelle Ähnlichkeiten auf mit dem bekannten ‚Turing-Test‘, welcher von Alan Turing 1950 vorgeschlagen wurde: Turing – https://de.wikipedia.org/wiki/Alan_Turing, Turing-Test – https://de.wikipedia.org/wiki/Turing-Test
Eine ungewöhnliche KI-Mensch Analogie
Wenn Menschen Computer beschreiben, dann kommt der Benutzer, der Mensch zwar als ‚Anwender‘ noch vor, aber tiefer gehende Vergleiche zwischen Computern und Menschen finden kaum statt. Beliebt ist allerdings das Stichwort ‚Gehirn‘: durch den Einsatz von ‚künstlichen neuronalen Netzen (KNN)‘ [1] wird oft und gerne die Hypothese in den Raum gestellt, dass Computer mit den künstlichen neuronalen Netzen die Leistungen des menschlichen Gehirns (welches aus ca. 80 Milliarden Gehirnzellen besteht) ‚im Prinzip‘ nachbilden und prinzipiell auf Dauer ‚übertreffen‘ können.
Bevor in diesem Text auf diese Frage weiter eingegangen wird — sie gehört unzweifelhaft zu einem Aspekt der Frage ‚Feind‘ oder ‚Freund‘ — soll der Vergleich zwischen KI und Mensch durch eine etwas ungewöhnliche Analogie befeuert werden: Wir nehmen die zuvor eingeführten 6 Komponenten eines modernen Computersystems als ‚Bezugspunkt‘, um zu verdeutlichen, welche Strukturen wir beim Menschen in Anschlag bringen müssen. Also, die grobe Anordnung für ein Gedankenexperiment sieht wie folgt aus:
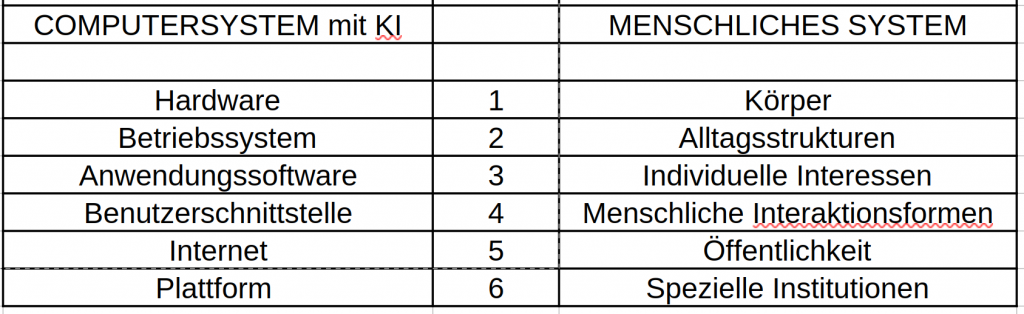
TABELLE : Vorschlag einer ‚Analogie‘ zwischen Computersystemen mit KI und einem gesellschaftlichen System mit Menschen
- Die Gegenüberstellung von ‚Hardware‘ zu ‚Körper‘ auf Ebene 1 ist vielleicht noch nachvollziehbar : die ‚Basis des Menschen ist sein Körper. Statt aus Metall und vielen ‚Computer-Chips‘ besteht der Körper aus mehr als 36 Billionen (1012) biologischen Zellen, die auf hoch-komplexe Weise miteinander im konstanten Austausch stehen.
- Die Gegenüberstellung von ‚Betriebssystem‘ und ‚Alltagsstrukturen‘ auf Ebene 2 ist möglicherweise ‚ungewöhnlich‘ : Das Betriebssystem reguliert beim Computer den Zugriff auf die Hardware. Beim Menschen legen die vereinbarten Regelsysteme und Rollen im Alltag fest, was ein Mensch mit seiner Körperlichkeit tun kann bzw. nicht tun kann! Je nach Land und Kultur kann der Alltag ganz unterschiedliche ‚formatiert‘ sein.
- Mit der Anwendungssoftware auf Ebene 3 werden spezielle Nutzungsinteressen unter Verwendung des Betriebssystems beschrieben. Im Fall des Menschen können dies die ‚individuellen Interessen‘ eines Menschen sein, für die der Mensch in seiner Alltagsstruktur nach möglichen ‚Umsetzungen‘ (‚Realisierungen‘, ‚Verwirklichung‘) suchen kann.
- Während auf Ebene 4 mit der ‚Benutzerschnittstelle‘ eines Computersystems beschrieben wird, auf welche Weise ein Mensch mit einem Computer interagieren kann, gibt es für Menschen im ‚Umgang mit anderen Menschen‘ Regelsysteme (ein Rechtssystem, religiöse Regeln, moralisch-ethische Wertesysteme …) , welche ausdrücken, was in welcher Situation ‚getan werden sollte‘ bzw. ’nicht getan werden sollte‘.
- Die Vernetzung von einzelnen Computersystemen über ein ‚Netzwerk‘ (spezielle über das Internet) auf Ebene 5 hat eine gewisse Entsprechung in der ‚Öffentlichkeit‘ im Kontext eines Alltags. Die Öffentlichkeit kann für ganz unterschiedliche Kommunikationsformen genutzt werden, um Gedanken, Ideen, Wünsche usw. zwischen Menschen auszutauschen, nicht nur an einem einzigen Ort, sondern prinzipiell überall, mit jedem (soweit die Strukturen des Alltags dies zulassen).
- Im Rahmen des Internets konnten sich ‚Plattformen‘ ausbilden, Ansammlungen von vielen Computern, die untereinander verbunden mit ihrer Software hoch komplexe Leistungen für ‚viele Nutzer gleichzeitig‘ anbieten können. Eine Entsprechung zu ‚Plattformen im Internet‘ können auf Ebene 6 beliebig umfangreiche ‚Institutionen‘ sein, welche Menschen bilden können, um an einem Ort hoch komplexe Leistungen zu ermöglichen, die dann über eine Öffentlichkeit vielen anderen Menschen verfügbar gemacht werden können.
Diese Gegenüberstellung eröffnet die Möglichkeit, das Verhältnis von Mensch & KI in einem differenzierten Kontext zu betrachten als sonst üblich.
[1] Siehe den sehr guten Überblick hier: https://de.wikipedia.org/wiki/K%C3%BCnstliches_neuronales_Netz
DIE ERSCHAFFUNG DES ERSTEN GROSSEN AKTIVEN SPIEGELS
Nach Einführung einer Analogie mit 6 Ebenen zwischen KI und Menschen eröffnet sich die Möglichkeit, am Beispiel einer ’speziellen Form von KI‘, nämlich der sogenannten ‚generativen KI‘, zu verdeutlichen, wie die ‚Erschaffung‘ einer bestimmten Form von KI durch den Menschen letztlich kein ‚wirkliches Gegenüber‘ erschafft, sondern nur einen ‚großen Spiegel‘ für den Menschen, welcher die Eigenschaften der Menschen nicht vollständig und auch nicht ‚1-zu-1′ widerspiegelt, sondern das ’sprachliche Bild der Menschen‘ zwar zurückspiegelt, aber ‚aktiv verändert‘!
Diese Technologie markiert in der Evolution der Menschen einen Meilenstein.
Hier eine kurze Beschreibung dieses Meilensteins mit seinen ungeheuren neuen Möglichkeiten für das ‚Selbstverständnis‘ der Menschen und ihrer Kommunikation untereinander (ein Freund?). Im Einsatz dieser neuen Technologie wird aber auch deutlich, dass der einzelne Mensch in Interaktion mit dieser neuen Technologie sich ganz real emotional und kognitive ’selbst entmächtigen‘ kann (ein Feind?)! Bei hundert Tausenden von Menschen, vielleicht sogar Millionen, geraten Menschen in eine Abhängigkeit von ihrer Interaktion mit dieser neuen Technologie, in der sie ihre eigene Position weitgehend — oder sogar ganz — verlieren.
Schauen wir uns dies genauer an.
Die Ebenen 8-11 sprengen die Analogie der Ebenen 1-6
In der Analogie der Ebenen 1-6 standen sich zwei Strukturen gegenüber: auf der einen Seite die komplexe Struktur heutiger vernetzter Computer — mit KI — und auf der anderen Seite die komplexe Struktur von menschlichen Gesellschaften in denen sich der einzelne Mensch vorfindet.
Solange man davon ausgeht, dass es Computer in dieser komplexen vernetzten Anordnung gibt, kann man das Verhältnis zwischen existierenden Computern und existierenden Menschen ‚äußerlich‘ dadurch beschreiben, dass man ausschließlich die ‚beobachtbaren Interaktionen‘ zwischen beiden beschreibt.
Für ein volles Verständnis für das, was da jeweils passiert, ist dies aber absolut zu wenig! Aus Sicht des Menschen geht es nicht nur darum, irgendwelche Handlungen (Schreiben, Sprechen, Malen, …., Lesen, Hören, …) vorzunehmen, sondern jegliche Handlung ist im ‚Innern des Menschen‘ eingebettet in ein hoch komplexes Netzwerk von Wahrnehmungen, Erinnerungen, Denkoperationen, alle zusätzlich eingebettet in ein komplexe Welt von Emotionen, um nur das Wichtigste zu nennen. Das tatsächliche ‚Selbstverständnis‘ des Menschen ist in diesem komplexen — und dynamischen! — Innern verankert. Um also einzelne beobachtbare Interaktionen ‚verstehen‘ zu können, muss man dieses aktive Innere des Menschen für ein ‚Verstehen dieser Interaktionen‘ mit einbeziehen, was bekanntlich nicht einfach ist.
Im Fall des Computers auf der anderen Seite ist das ‚Verstehen‘ des ‚maschinellen Innern‘ bei der heutigen Komplexität der Technologie rein praktisch oft auch nur bedingt möglich, aber man kann zumindest ‚im Prinzip‘ diese Technologie aufgrund der durchgehenden Mathematisierung rekonstruieren und daraus verbindliche Aussagen ableiten.
Im Folgenden werden jetzt 4 Perspektiven beschrieben, die man auch als ‚Ebenen‘ mit Bezug auf die Ebenen 1-6 ansehen kann, allerdings sind dies eher ‚Meta-Ebenen‘ zu den Ebenen 1-6, da sie die Analogie der Ebenen 1-6 von einem anderen ‚Blickwinkel‘ aus betrachten.
Im Rahmen der Meta-Ebenen 8 – 11 wird nicht das ganze Konzept einer ‚KI‘ betrachtet, sondern nur das Beispiel einer ’speziellen KI‘ im Format einer ‚generativen KI (gen-KI)‘. [1] Dies liegt daran, dass dieses spezielle Format seit November 2022 den Alltag von ganz vielen Menschen weltweit durchdringt.
BILD1 : Handskizze der Meta-Ebenen 8 – 11. Zum Bild und seiner Erläuterung siehe den ANHANG.
ANMERKUNGEN
[1] Eine Beschreibung von ‚generativer KI‘ aus mathematischer Sicht findet sich hier: https://de.wikipedia.org/wiki/Generatives_KI-Modell . Eine eher anwendungsorientierte Sicht wurde im Vortrag Nr.2 beschrieben: https://www.oksimo.org/2025/09/11/mensch-ki-risiko-oder-chance-wie-denkt-chatgpt-erweiterter-bericht-vom-mittwoch-3-sept-2025-20-22h/
Die Erschaffung eines Plans für eine ‚generative KI (genKI)‘ – Meta-Ebene 8
Im Kontext der bisherigen Analogie mit den Ebenen 1 – 6 wird nicht sichtbar, dass es zwischen der Technologie der Computer und einer menschlichen Gesellschaft eine grundlegende ‚Asymmetrie‘ gibt : während es Menschen als Teil des übergreifenden (biologischen) Lebens ‚aus sich heraus‘ gibt (Prozess der Evolution als Verlängerung der Entstehung des Universums), gibt es Computer erst dadurch, dass Menschen sich ‚dies ausgedacht‘ haben, zunächst einfach als ‚Bilder ‚ / als ‚Konzepte‘ im Kopf‘. Bei dieser ‚Entstehung des Konzepts‘ waren nicht alle Menschen beteiligt sondern nur eine vergleichsweise kleine Gruppe von ‚Experten‘, die in der ersten Hälfte des 20.Jahrhunderts über das notwendige ‚Know-how‘ verfügten.
Die Transformation menschlicher Sprach-Dokumente in ein Modell – Meta-Ebene 9
Ein Teil des ‚Konzepts gen-KI‘ besteht darin, die ‚Ausdrucksseite‘ der menschlichen Sprache, so, wie sie in öffentlich zugänglichen Dokumenten im Internet vorliegt, in ein ‚Sprachmodell‘ umzuformen (‚abzubilden‘, zu ‚transformieren‘,…), welches die Elemente der Ausdrucksseite umfasst, ergänzt um Informationen über die ‚Abstände‘ zwischen diesen Elementen in komplexen Ausdrücken, sowie um Informationen über die ‚Häufigkeit‘, mit der Elemente von anderen Elementen begleitet werden. Diese Kombination aus isolierten Einzelelementen verbunden mit einer ’statistischen Dynamik‘ bietet die Voraussetzung dafür, dass sich bei geeigneter Nutzung dieses Sprachmodells ‚ähnliche Ausdrücke‘ daraus ‚generieren‘ lassen.
Zu beachten ist hierbei, dass es sich ’nur‘ um die ‚Ausdrucksseite‘ der Sprache handelt ‚ohne jegliche Bedeutung‘! Damit ist von vornherein festgelegt, dass es völlig offen ist, in welchem Bezug zur erfahrbaren Wirklichkeit mögliche generierte sprachliche Ausdrücke auf der Basis dieses bedeutungslosen Sprachmodells stehen: der Aspekt von ‚Zutreffen‘ (‚wahr‘) oder ‚Nicht-Zutreffen‘ (‚falsch‘) ist selbst nicht Teil des Sprachmodells.
Das Sprachmodell basiert nicht nur auf der Ausdruckstätigkeit von Menschen, sondern es sind wiederum die Menschen selbst, welche eine Umformung der vorliegenden Sprachdokumente in dieses spezielle Sprachmodell erarbeitet haben.
Festlegung eines Interaktionsmusters zwischen Sprachmodell und menschlichem Benutzer – Meta-Ebene 10
Da das Sprachmodell selbst rein statisch ist, welches zudem für die Nutzung von Algorithmen als reine Zahlenstruktur vorliegt, enthält das Konzept für eine gen-KI auch einen Teil, der explizit die möglichen Interaktionen zwischen einem menschlichen Benutzer und dem Sprachmodell beschreibt.
Dieses Konzept beschreibt ein ‚Dialogmodell‘ zwischen dem menschlichen Benutzer und dem Sprachmodell, welches so beschaffen ist, dass es auf mögliche ’sprachliche Eingaben‘ seitens des menschlichen Benutzers in einer Weise ’sprachlich antwortet‘, wie es der menschliche Benutzer aus ‚alltäglicher sprachlicher Kommunikation‘ gewohnt ist.
Die notwendigen ‚Muster für die Dialoge‘ müssen eigens auf der Basis tatsächlicher Dialoge identifiziert und in geeignete ‚Muster‘ transformiert werden. Der dafür notwendig Algorithmus (ein Software-Programm) musste speziell ‚trainiert‘ werden, um je nach Eingabe des menschlichen Benutzers mit dem ‚passenden Muster‘ zu reagieren. Diesen für die Dialoge ‚zuständigen Algorithmus‘ nennt man meistens ‚Chatbot‘. Auf den Menschen wirkt solch ein Chatbot-Algorithmus‘ wie ein ‚menschlicher Gegenüber‘, weil er sich ’sprachlich ausdrückt‘ und diese ’sprachlichen Ausdrücke‘ jenen von Menschen ‚täuschend ähnlich‘ sind.
Ein großer aktiver Spiegel – Meta-Ebene 11
Die ‚Ähnlichkeit‘ der sprachlichen Antworten eines Chatbot-Algorithmus mit menschlicher sprachlicher Kommunikation ist möglich, weil die sprachliche Eingabe des menschlichen Benutzers in das Sprachmodell ‚hinein projiziert‘ wird und aufgrund der ’statistischen Dynamik‘ des Sprachmodells ‚findet‘ der Algorithmus ‚passende sprachliche Ausdrücke‘, welche jenen ähneln, die Menschen in dieser Situation auch benutzen könnten.
Wohlgemerkt: der Algorithmus hat keine Ahnung von irgendwelcher ‚Bedeutung‘! Er benutzt nur die statistische Dynamik, welche jedem sprachlichen Ausdruck quasi ‚eingebaut‘ ist. In dieser statistischen Dynamik manifestiert sich das ‚Bedeutungswissen‘ von Menschen, insofern die ‚Bedeutung‘ eines sprachlichen Elements bei der Sprachproduktion darüber entscheidet, welche andere Bedeutung dazu ‚passt‘, und dementsprechend wird das ‚zur Bedeutung passende sprachliche Element‘ ausgewählt. Das gemeinsame Auftreten verschiedener Sprachelemente in einem sprachlichen Ausdruck ist beim Menschen daher im Normalfall ’nicht zufällig‘!
Ein ‚Dialog‘ zwischen Chat-bot Algorithmus und menschlichem Benutzer besteht aus einer Folge von ‚Mini-Dialogen‘. Ein Mini-Dialog besteht aus zwei Elementen: eine Eingabe seitens des menschlichen Benutzers und einer Reaktion seitens des Chat-bot Algorithmus. Danach kann der Dialog abbrechen oder es folgt ein weiterer Minidialog. Dabei ist zu beachten, dass der Chat-bot Algorithmus ‚intern‘ einen ‚Kontext‘ aufbaut, in dem alle Mini-Dialoge in ihrer Abfolge gespeichert werden. Dies bedeutet, dass der aktuelle Mini-Dialog im Lichte des Kontext-Speichers eventuell nur ‚ein Element in einer ganzen Abfolge von Mini-Dialogen‘ ist. Dies hat Auswirkungen darauf, welche Aspekte des Sprachmodells ‚aktiviert‘ werden.
Sieht man von diesen ‚technischen Details‘ ab, dann ‚erlebt‘ der menschliche Benutzer ein ‚Gegenüber‘, das sich sprachlich ‚wie ein anderer Mensch‘ verhält (hier passt der Verweis auf den berühmten Turing-Test). [1] Jeder normale menschliche Benutzer, der nicht zufällig ein Experte für gen-KI Systeme ist, wird sein ‚Gegenüber‘ im Normalfall nicht nur als ‚menschlich‘ erleben, sondern er wird auf ihn auch entsprechend reagieren. Nicht wenige menschliche Benutzer verfallen in echte Bewunderung für ihr algorithmisches Gegenüber, scheint dieser doch aus der Perspektive des individuellen menschlichen Benutzers über erheblich mehr Wissen zu verfügen.
Tatsache ist — aus der Gesamtperspektive betrachtet –, dass der menschliche Benutzer — vermittelt durch den Chat-bot Algorithmus — nichts anderem begegnet als ’sich selbst‘, nicht als Individuum, sondern über die Ausdrucksmenge einer unfassbar großen Zahl von Menschen. Letztlich schaut er in eine Art von Spiegel, der aus all den Texten besteht, die viele Millionen Menschen ‚hervorgebracht‘ haben, und deren Ausdrücke mit Hilfe des Chat-bot Algorithmus ’sichtbar‘ gemacht werden.
Das Wunderbare ist, dass er sein eigenes beschränktes Wissen in ‚Resonanz‘ bringen kann mit dem Wissen von vielen Millionen anderer Menschen. Der vermittelnde Chat-bot Algorithmus selbst weiß gar nichts, er ist aber darauf ausgelegt, dass er dem einen menschlichen Benutzer die große Weite des Wissens von vielen Millionen Artgenossen über die Ausdrucksseite dieses Wissens zur Kenntnis bringen kann.
Die spontane Bewunderung, die viele menschlichen Benutzer dem Chat-bot Algorithmus gegenüber empfinden, sollten sie daher eigentlich den Menschen gegenüber empfinden, die durch diese Dialoge sichtbar werden, und damit erfährt der einzelne Nutzer auch indirekt etwas über sich selbst als Mensch: er selbst, der einzelne Nutzer, ist nicht alleine, sondern er ist Teil von diesem wunderbaren großen Wissen einer ‚Gemeinschaft von Menschen.
Nachbemerkung
Wenn man dem Chat-bot Algorithmus — hier ChatGPT5 –, diesen strukturellen Sachverhalt als Text vorlegt, dann kann er diese Struktur tatsächlich verbalisieren (ChatGPT5 am 3.Nov 2025: „KI ist die Resonanzstruktur, durch die das Menschliche sich selbst erkennt.„), allerdings verhindert sein aktuelles ‚Design‘ (von Menschen gemacht), dass er diese ‚aktive Spiegelstruktur‘ in sein Dialogverhalten einbaut.
ANMERKUNGEN
[1] Der ‚Turing-Test‘ geht zurück auf Alan M.Turing, welcher ihn 1950 vorgeschlagen hatte: Turing – https://de.wikipedia.org/wiki/Alan_Turing, Turing-Test – https://de.wikipedia.org/wiki/Turing-Test
RISIKO (Feind?) oder CHANCE (Freund?)?
Greifen wir an dieser Stelle das Leitthema der gesamten Vortragsreihe auf „Mensch & KI : Risiko oder Chance?“
Auf welch vielfältige Weise Menschen für andere Menschen zu ‚Feinden‘ werden können, das wissen wir aus der Geschichte der Menschheit zur Genüge, und auch die Gegenwart bietet reale Beispiele, die furchtbarer kaum sein können. Entsprechendes gilt aber auch für die Kategorie ‚Freund‘ : neben dem ‚Schrecken‘ des Feindes gibt es bis heute — zum Glück — auch solche Menschen, die anderen Menschen auf vielfache Weise ‚gut tun‘.
Was bedeutet ‚Feind‘ oder ‚Freund‘ in unserem Fall, in dem ein Algorithmus von Menschen erschaffen worden ist, um zwischen den öffentlich zugänglichen Texten von Millionen von Menschen in sehr detaillierter Weise eine ‚Resonanz‘ herzustellen zum individuellen Wissen eines menschlichen Benutzers. Kann dieser Algorithmus in dieser speziellen Funktion ein ‚Feind‘ oder ein ‚Freund‘ sein?
Die Rolle des ‚Feindes‘
Nr.1 Im Kern neutral‘ …
Da das Sprachmodell ausschließlich aus Zahlen mit einer statistischen Dynamik besteht, muss der Algorithmus des Dialog-Chat-bots, der ‚in das Sprachmodell hinein‘ projiziert und ‚Ergebnisse der Projektion‘ dann an den menschlichen Benutzer ausgibt, völlig allgemein ausgelegt sein (Nr.1). Der Algorithmus selbst kann in dieser Position nichts ‚Negatives‘ für den individuellen Benutzer tun.
Nr.2 Ohne Bedeutungswissen ’nicht Wahrheitsfähig‘
Trotz dieser ‚eingebauten Neutralität‘ gegenüber dem Sprachmodell (Nr.1) kann der Algorithmus des Dialog-Chat-bots für den menschlichen Benutzer dennoch ‚gefährlich‘ werden, weil das Sprachmodell selbst über keinerlei ‚Bedeutung‘ verfügt (Nr.2). Das ‚Fehlen‘ jeglicher Bedeutung nimmt dem Algorithmus des Dialog-Chat-bots die Möglichkeit, zu beurteilen, wie eine sprachliche Formulierung ‚zur Wirklichkeit‘, zur ‚realen Welt‘ steht. Jeder Mensch kann einen sprachlichen Ausdruck ‚im Lichte seines Bedeutungswissens‘ mit der ihm ‚bekannten‘ und ‚erfahrbaren Welt‘ ‚abgleichen‘ : trifft die potentielle Aussage des sprachlichen Ausdrucks auf die reale Welt ‚zu‘ (Ist der Ausdruck ‚wahr‘) oder trifft der Ausdruck ’nicht zu‘ (Ist der Ausdruck falsch‘) oder ist er aktuell ‚unentscheidbar‘? Der Algorithmus des Dialog-Chat-bots verfügt nicht über diese Entscheidungsmöglichkeit. Er kann daher ‚Antworten‘ für seinen menschlichen Benutzer generieren, die im Rahmen seines Algorithmus OK sind, für den Weltbezug seines Benutzers aber können sie ‚falsch‘ sein. Diese ‚Blindheit‘ gegenüber dem ‚Zutreffen‘ oder ‚Nichtzutreffen‘ von sprachlichen Ausdrücken ist für den Algorithmus des Dialog-Chat-bots ‚eingebaut‘ und daher nicht behebbar.
Man müsste hier daher eher von einer ’strukturellen Schwäche‘ des Algorithmus sprechen, nicht von einem möglichen ‚bewussten Fehlverhalten‘. Es bleibt der Verantwortung des menschlichen Benutzers überlassen, sich um eine abschließende Kontrolle des Zutreffens / Nichtzutreffens zu kümmern.
Nr.3 ‚Verunreinigtes Internet‘
Durch das strukturelle Problem des fehlenden Bedeutungswissens (Nr.2) gibt es eine reale Quelle von Bedrohung durch die öffentlich zugänglichen Dokumente, die in das Sprachmodell eingehen: alle Dokumente stammen (vor der Zeit der gen-KI) von Menschen. Menschen können auch ‚Unsinniges‘ oder ‚Falsches‘ schreiben, unbewusst oder ganz bewusst (z.B. im Rahmen von ‚Propaganda‘). (Nr.3) Wenn solche Dokumente Eingang in das Sprachmodell finden, dann wird der Algorithmus des Dialog-Chat-bots diese unsinnigen/ falschen Dokumente genauso behandeln, wie alle anderen auch. Dies bedeutet, bei der ‚Projektion in das Sprachmodell‘ können Antworten entstehen, die aus eben solchen unsinnigen oder falschen Dokumenten stammen. Der Algorithmus des Dialog-Chat-bots wird diese Antworten ohne speziellen Bemerkungen ausgeben (soweit es nicht andere Dokumente gibt, die eine ganz andere Formulierung vorschlagen). Damit werden dem menschlichen Benutzer Sichtweisen der Welt vermittelt, die unsinnig bzw. falsch sind.
Obgleich also der Algorithmus des Dialog-Chat-bots selbst ’neutral‘ ist gegenüber Dokumenten, können ‚im Ursprung unsinnige/ falsche‘ Dokumente bis zum menschlichen Benutzer gelangen und ihn falsch informieren. Der Algorithmus des Dialog-Chat-bots selbst ist nicht ‚böse‘, aber die gesamte ‚Struktur‘, in die er eingebettet ist, kann durch das Vorkommen ‚falscher Beschreibungen‘ auf eine Weise ‚böse‘ sein, dass dieses ‚Böse‘ an den menschlichen Benutzer als Antwort ‚weiter vermittelt wird‘.
Diese ‚Bosheit‘ hat ihre Wurzeln in den ‚Urhebern‘ der öffentlichen Dokumente, und diesen waren — bis vor der Aktivität von gen-KI — normalerweise ‚Menschen‘. Also ist das ‚potentiell Böse‘ bei den ‚Menschen‘, bei ‚uns selbst‘ zu lokalisieren.
Nr.4 ‚Hybride Form von Bosheit‘
Mit der Existenz von gen-KI in Kooperation mit Menschen gibt es aber auch noch eine neue ‚hybride Form von Bosheit‘ (Nr.4) : Der Algorithmus des Dialog-Chat-bots ist so ausgelegt, dass er seine ‚Antworten‘ mittels der ’statistischen Dynamik‘ generiert, die in dem Sprachmodell durch die Struktur der Sprache selbst angelegt ist. Die ‚Antworten‘ sind niemals ‚logische Schlüsse‘, wie wir Menschen sie machen können, sondern sie sind aufgrund von Wahrscheinlichkeiten mit den vorfindbaren Sprachelementen generiert. Dadurch können jederzeit ’neue sprachliche Ausdrücke‘ entstehen, die einer Art ‚blinder Kreativität‘ entsprechen. Diese sprachlichen Ausdrücke einer ‚blinden Kreativität‘ können ‚gut klingen‘, haben aber einen ‚verzerrten‘ oder ‚gar keinen Bezug zur Realität.
Wenn solche Ausdrücke in Texten vorkommen, die menschliche Benutzer im Dialog mit dem Algorithmus des Dialog-Chat-bots erstellen lassen, und die sie dann — ohne angemessene Kontrolle — wieder öffentlich ins Internet stellen, dann nimmt der Grad der ‚Verunreinigung‘ der öffentlichen Dokumente real zu.
Die Rolle des ‚Freundes‘
BILD3 : Handskizze zur Rolle des ‚Freundes‘. Zum Bild und seiner Erläuterung siehe den ANHANG.
Nachdem zuvor ein wenig sichtbar wurde, dass und wie der Algorithmus des Dialog-Chat-bots schädlich sein kann, obwohl er selbst ’neutral‘ ausgelegt ist, sollen hier jetzt einige Aspekte sichtbar gemacht werden, durch die der gleiche Algorithmus auch in der Rolle des Freundes wirksam werden kann.
Neben verschiedenen individuellen Aspekten eines menschlichen Benutzers, die für sein ‚Erleben des Algorithmus des Dialog-Chat-bots‘ bedeutsam sein können, soll hier das Augenmerk auf die ‚Wissenssituation‘ des einzelnen menschlichen Benutzers gerichtet werden.
Nr.1 – 3 Individuelle Wissenssituation
So viel ‚Wissen‘ ein einzelner Mensch im Laufe seines Lebens auch einsammeln konnte, sein individuelles Wissen bleibt ‚endlich‘, ‚fragil‘, ‚fehlerbehaftet‘ (Nr.1). Durch Kommunikation mit seinem ‚Umfeld‘ (Nr.2) kann er manche Aspekte weiter abklären, kann andere modifizieren, kann sein Wissen weiter anreichern. Doch auch das Wissen aus der Umfeld-Kommunikationen ist endlich, fragil, und kann fehlerhaft sein. Bezieht man die Vielfalt der Menschheit weltweit mit ein (Nr.3), dazu auch noch den Aspekt des ‚beständigen Wandels‘, dann ist es eine nahezu unlösbare Aufgabe für einen einzelnen Menschen, mit diesem globalen Wissen mitzuhalten.
Nr.4-5 Globale ‚Wissensrepräsentationen‘
Glücklicherweise haben die Menschen im Laufe der Geschichte ‚Techniken‘ entwickelt, wie man das ‚Wissen von Vielen‘ sammeln und verfügbar machen kann. In früheren Jahrtausenden war dies das Zauberwort ‚Bibliothek‘. Seit wenigen Jahrzehnten ist das Zauberwort heute ‚Internet-Enzyklopädie‘ und überhaupt das gesamte Internet, sofern das Internet frei zugänglich ist (Nr.4).
Die frei zugänglichen Dokumente des Internets repräsentieren zwar nicht das ‚gesamte Wissen‘ der Menschheit, aber doch einen erheblichen Teil, der weit über das hinausgeht, was Bibliotheken früher und auch heute leisten können. Für einen einzelnen Menschen eröffnet dies zumindest die prinzipielle Möglichkeit, von diesem global zugänglichen Wissen Gebrauch zu machen. Jeder, der dies versucht, merkt sehr schnell, dass die üblichen Suchverfahren sehr begrenzt und sehr unzuverlässig sind. Man freut sich dann, wenn man auf ‚Wissens-Inseln‘ stößt, die von Menschen stark ’strukturiert/ geordnet‘ worden sind, um das Suchen zu erleichtern. Nicht wenige dieser strukturierten Wissens-Inseln sind aber nicht frei zugänglich. Eine der berühmtesten — und wohl auch besten — Ausnahmen ist hier sicher ‚Wikipedia‘.
So großartig diese Ansammlung freier Texte im Internet ist, für einen einzelnen Menschen ist es dennoch nahezu unmöglich, zu bestimmten Fragen genau jene Texte zu finden, die dazu ‚passen‘.
An dieser Stelle kommt seit 2022 als neuer Lösungsansatz das Konzept eines ‚Sprachmodells‘ (Nr.5) ins Spiel, welches aus einer großen Gesamtheit von öffentlichen Texten (viele Millionen) diese Texte nicht einfach nur als ‚ganze Texte‘ sammelt, sondern diese in lauter ‚Einzelteile‘ (Elemente sprachlicher Ausdrücke) zerlegt und dann als einen ‚Zahlenraum‘ aufbaut, in dem alle Elemente unter Berücksichtigung ihrer Beziehungen untereinander samt Häufigkeiten vorkommen. Dies bedeutet, dass ein geeigneter Suchprozess nicht einfach nur immer ganze Texte finden kann, sondern die ‚Worte der Suchanfrage‘ bilden einen ‚Schlüssel‘, der innerhalb des Sprachmodells genau jene sprachlichen Ausdrücke finden kann, die in der ‚Gesamtheit des Sprachmodells‘ der Suchanfrage am meisten ‚ähneln‘. Von dieser ‚Fundstelle‘ aus können dann weitere ’statistisch zusammenhängende‘ sprachliche Elemente gefunden werden.
Anders formuliert: diese Suche im Raum eines speziellen Sprachmodells führt primär nicht zu Dokumenten, sondern sie führt direkt zu ‚Wissen‘, sofern es ‚als sprachliche Formulierung‘ vorliegt. Dies ist irgendwie genial, hat aber die Schwäche, dass es die größeren Wissenszusammenhänge unsichtbar macht.
Immerhin, das Positive, ein einzelner Mensch mit seinem unvermeidbar begrenzten Wissen kann auf sprachlich repräsentiertes Wissen aus Bereichen stoßen, welches dem Fragenden ansonsten unzugänglich wäre.
Nr.6 Unterwegs zum Großen Ganzen?
So begrenzt die konstruktiven Möglichkeiten der neuen gen-KI basierten Interaktionsformate noch sind (und so deutlich auch die möglichen negativen Effekte), so kann man doch zumindest erahnen, welche Möglichkeiten die Menschen sich eröffnen, wenn sie diese neue Technologie bewusst einsetzen : der einzelne kann — wenn auch immer noch begrenzt — eine ‚Brücke‘ schlagen zu dem ‚großen Ganzen des menschlichen Wissens‘.
WIE KANN ES WEITER GEHEN?
KI – Gesellschaft – Zukunft
Die generative KI ist nur ein Teil von KI
Die grundsätzliche Frage nach dem Verhältnis zwischen moderner KI (lokalisiert auf großen Plattformen, eingebettet in das weltweite Internet) und dem Menschen (ebenfalls eingebettet in komplexe Alltagsstrukturen) wurde im Text mehr und mehr eingeengt auf eine spezielle Form von KI (die sogenannte generative KI (gen-KI)) und auf die Situation einzelner Menschen, die mit einer generativen KI interagieren. Die ‚Welt‘ existiert für die generative KI als ein ‚Sprachmodell‘, welches als ein ‚eingefrorener Zustand‘ vorliegt. Die ad-hoc Einbeziehung von aktuellen Webseiten ändert an dieser Grundsituation nichts.
Natürlich stellen sich hier einige Fragen, z.B.: Wie verhält sich gen-KI zur allgemeinen KI? Was ist überhaupt KI? Wie verhält sich maschinelle Intelligenz (= KI) zur menschlichen Intelligenz?
Dazu kommt auch die Einschränkung des ‚Faktors Mensch‘ auf Einzelpersonen.
Der ‚einzelne Mensch‘ ist eine schlechte Abstraktion
Die Fokussierung auf ‚individuelle Personen‘ als ‚Nutzer einer generativen KI blendet faktisch alles aus, was einen Menschen ausmacht: ein Mensch ist immer ‚Teil einer Gemeinschaft‘; er ist eingebettet in ‚Alltagsprozesse‘; jeder Mensch hat vielfältige ‚Interessen‘ und ‚Ziele‘; Menschen bilden nach Bedarf komplexe Organisationen; Menschen können eine ‚gemeinsame Öffentlichkeit‘ bilden, über die alle kommunizieren können; es gibt ‚Staaten‘ mit gemeinsamen übergreifenden Regeln (Verfassungen) und den dazu gehörigen Organisationen; es gibt zahllose spezielle Prozesse zu Themen wie Bildung, Ernährung, Gesundheit, Wohnen, Verkehr, Energie, Wirtschaft, Finanzen, Verteidigung und vieles mehr.
Für die Frage, ob und wie eine KI einem einzelnen Menschen helfen kann, sollte man die Situation des einzelnen Menschen im ‚Koordinatensystem seines Alltags‘ betrachten: welche Aufgaben hat er hier im Alltag zu erfüllen, zusammen mit all den anderen, um sich als Mensch ‚gut‘ zu fühlen?
Eine gemeinsame Zukunft?
In der ‚Hektik des Alltags‘, die jeden auf seine Weise absorbiert, kann die Frage der ‚Zukunft für uns alle‘ leicht aus dem Blick kommen. Eigentlich müsste es die Leitfrage für eine ganze Gesellschaft sein. Und, ja, die Zukunft der einzelnen sollte in solch einer ‚gemeinsamen Zukunft‘ ihren Platz haben können. Wie könnten all diese verschiedenen Anforderungen eingelöst werden?
Jeder, der sich schon mal mit der Ausarbeitung und Durchführung von Alltags-Prozessen beschäftigen musste, der weiß wie schwierig dies schon bei kurzfristigen Prozessen mit nur wenigen Beteiligten sein kann.
Vergrößert sich die Anzahl der Teilnehmer, wächst der Bedarf an benötigte Ressourcen und werden die Zeithorizonte größer, dann kann dies schon mal die Beteiligten auf vielfache Weise ‚überfordern‘. Und doch müssen die Aufgaben gelöst werden. Jede ’normale Kommune in Deutschland‘ ist solch ein Ort, wo sich beständig ganz viele solcher Prozesse ‚parallel‘ abspielen. Aufgaben müssen gelöst werden. Sachprobleme fragen nicht danach, ob die Menschen dazu gerade mal Lust haben; sie sind einfach da.
Und eine ‚Zukunft‘ ist kein ‚bekanntes Gelände‘; vieles ist unbekannt, ungewiss. Und man braucht wirklich einen ‚Plan‘, dazu ‚gemeinsame Ziele‘, ohne solche geht gar nichts. Wo kommen Ziele und Pläne her?
Schon diese einfache Aufzählung von Dimensionen unseres Alltags als Menschen lässt erahnen, dass eine KI mit einem ‚eingefrorenen Wissenskern‘ beschränkt auf ‚kunstvolle Erinnerungen‘ generiert aus der Vergangenheit, dazu ohne realen Weltbezug, für die Gesamtheit der Anforderungen an Menschen in einer Gemeinschaft kaum ausreicht.
Mit dieser für viele sicher unbefriedigenden kurzen Andeutung soll dieser Text hier enden.
Die Vortragsreihe ‚Mensch & KI : Risiko oder Chance?‘ wird aber weiter gehen. Es soll weiter versucht werden, die vielen spannenden Fragen um unsere menschliche Zukunft im Gegenüber zu diesen neuen KI-Technologien immer weiter zu klären.
